How Is Ray So Dang Fast?
If you’ve ever worked on a CPU-intensive distributed python project you know truly what pain feels like. Python’s global interpreter lock ensures that it’s impossible to run more than one operation at a time for an entire process. The age-old workaround is multi-processing. Rather than running one python process, run multiple processes and distribute work among them, but even this has its faults.
It just doesn’t work well if you need to communicate rapidly or with large volumes across process boundaries. Python’s multiprocessing communicates via pickling messages and sending them through shared file descriptors. The work of encoding, and decoding these messages in addition to the elaborate locking steps necessary to send information between processes renders this painfully slow.
So it shouldn’t come to a surprise that someone has figured out how to communicate across python processes better. Ray, a project started at UC Berkeley, is incredibly faster than standard python multiprocessing. It’s a python library built to support distributed python computing across process and on clusters of computers. Originally, it was built to run distributed ML models but at this point it’s used for many more applications than just that.
The reason: It’s wicked fast. In a simple benchmark it was shown that Ray is 5-25x times faster than python multiprocessing.
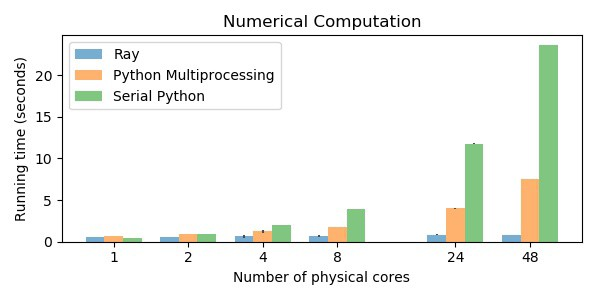
How? What Is This Dark Magic?
Two words: minimize copy. The authors of ray had a great idea to remove as many needs to copy data across boundaries as possible. They built a service called plasma which persists as a daemon and acts as a central object store that all python processes interact with to transfer data and coordinate with each other. The key was using shared memory as a means of transferring data. Other projects communicate via some central service over TCP like ZeroMQ or Redis but the point of failure in both is communicating large messages. TCP for inter-process communication simply pails in comparison to shared memory when you don’t have to copy your message to process it.
Plasma was built to minimize the amount of work in the encoding/decoding, for numpy arrays and other common python objects, plasma’s internal representation of data is identical to the interpreter’s. In those cases, there simply is no encoding/decoding step. That proves to be a game-changer.
When sending 10mb of data between processes can be measured in the micro-seconds. It opens things up that were not possible before.